多模态竞技场对标90B Llama 3.2!Pixtral 12B技术报告全公开

新智元报道
编辑:alan
【新智元导读】以开源极客之姿杀入江湖的Mistral AI,在9月份甩出了自家的首款多模态大模型Pixtral 12B,如今,报告之期已至,技术细节全公开。
作为欧洲的OpenAI,Mistral最近压力不小。
端侧小模型端不出来,对比评测的结果又遭到质疑。
上个月震撼登场的自家首款多模态大模型Pixtral 12B,也疑似遇到了成绩不如人的窘境。
不过世间纷扰,留待时间之中去见分晓。
毕竟Mistral AI当年也是以开源极客之姿杀入江湖的,以后的以后,圈内人总会想起有个一言不合就甩出磁力链的公司吧。
按照惯例,在9月份甩出多模态Pixtral 12B的开源链接之后,Mistral会在一段时间后放出技术报告。
我们来看一下Mistral家的第一个MMLM有什么新花样。

论文地址:https://arxiv.org/abs/2410.07073
开源代码:https://github.com/mistralai
首先,许多开源模型一般有个问题,就是为了多模态的性能而牺牲了本身的自然语言性能,之前英伟达的NVLM 1.0也谈到了这点。
Pixtral本次也是成功避开了这个缺陷,单单比较文本模型的性能,也在同等尺寸的模型中居于前列。
另一点与大多数模型不同的是,Pixtral选择从头开始训练了一个全新的视觉编码器。
基于此,Pixtral 12B输入图片的分辨率和长宽比不受任何限制,并且在128K的上下文窗口范围内,想放多少张图片都行!
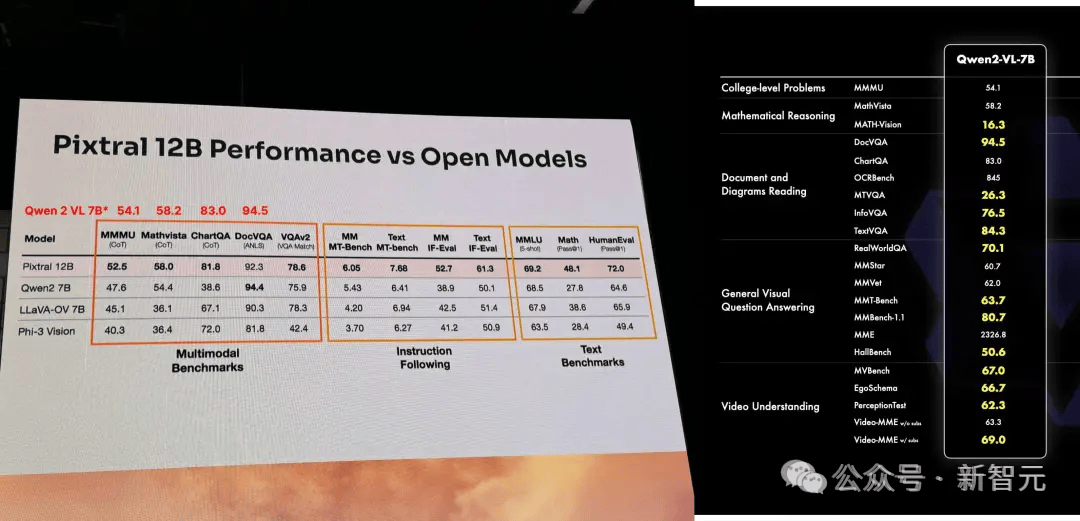
从论文的测试结果来看,Pixtral 12B明显优于其他类似大小的开源模型(比如Llama-3.2 11B和Qwen-2-VL 7B),
甚至在一些评测中,表现比Meta家的多模态老大哥Llama-3.2 90B还要好。
最后,与开源模型一起,Mistral还贡献了一个开源基准测试MM-MT-Bench,用于在实际场景中评估视觉语言模型。
技术细节
当前的多模态大模型基本上都是:模态编码器 + 投影模块 + 大语言模型主干。
如果需要多模态输出,后面还会对称地拼接投影层和各种解码器。
所以,在模型结构方面,我们可以分部分来看Pixtral都做了哪些工作。
模型结构
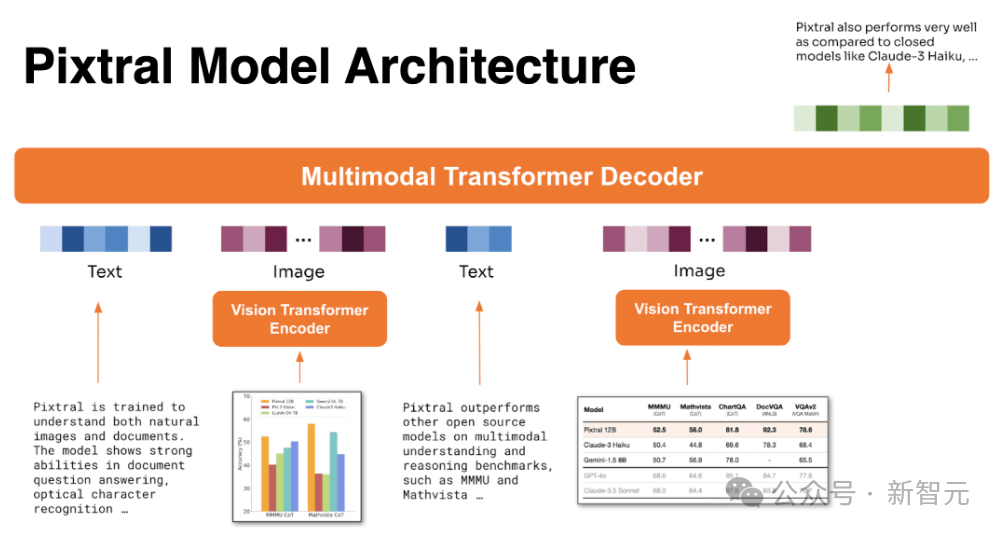
Pixtral 12B整体为Transformer架构,在大规模交错图像和文本文档上进行了预训练,具备多轮、多图像对话的能力。
多模态解码器
Pixtral的大语言模型主干选择了自家的Mistral Nemo 12B,decoder-only架构。
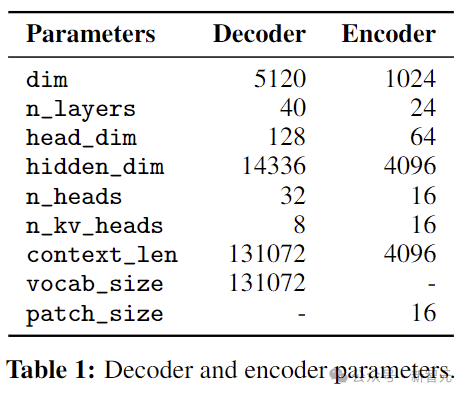
视觉编码器
视觉编码器部分是随Pixtral 12B一起新鲜出炉的PixtralViT。
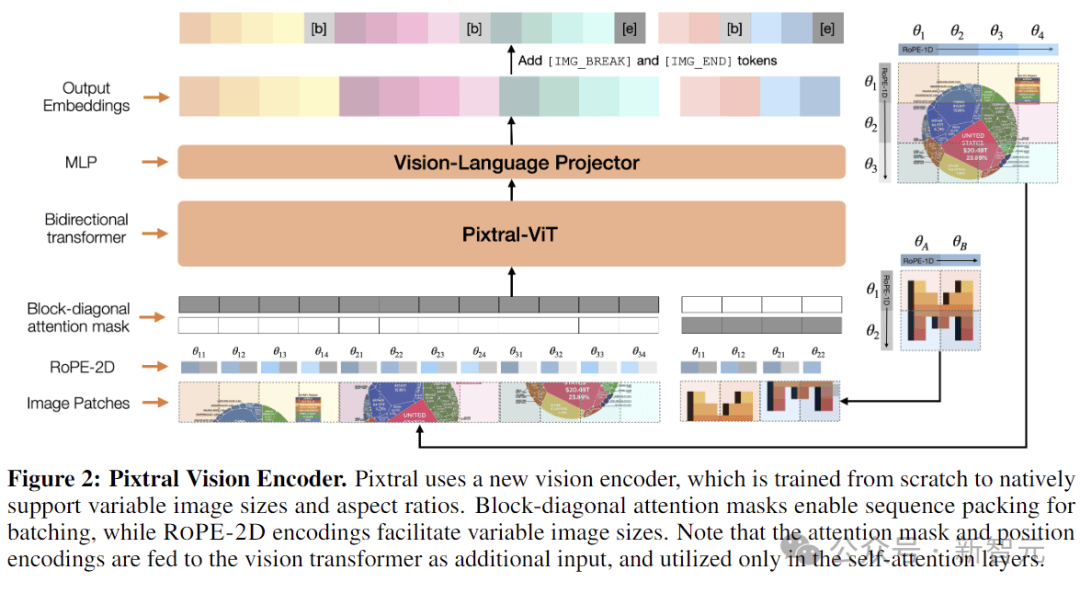
顾名思义,采用ViT架构打底,4亿参数量。同时为了能够处理各种分辨率和纵横比的图像,作者对标准架构进行了四项关键更改:
Break tokens:为了帮助模型区分具有相同patch数量(相同区域)但纵横比不同的图像,需要在图像行之间加入[IMAGE BREAK],在图像序列的末尾加上[IMAGE END]。
FFN中的门控:在隐藏层中使用门控,而非注意力块中的标准前馈层。
序列打包:为了在单个批次中有效地处理图像,作者沿序列维度将图像展平并连接起来,并构建了一个块对角掩码,以确保来自不同图像的patch之间没有注意力泄漏。
RoPE-2D:在自注意层中用相对旋转位置编码代替传统的绝对位置嵌入。虽然必须对学习到的位置嵌入进行插值以处理新的图像大小(通常以牺牲性能为代价),但相对位置编码自然而然地适合可变的图像大小。
RoPE-2D的变换可以表示为:
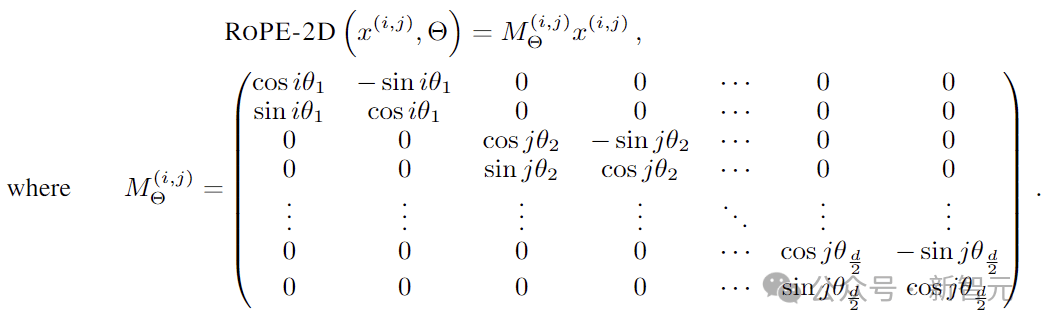
这样的设计可以自然地以原始纵横比适应高分辨率和低分辨率图像,从而显著提高多模态任务的性能。
相比之下,传统的编码器一般就是针对ImageNet训练的,分辨率为224 × 224或336 × 336。
完整架构
Pixtral的视觉编码器通过两层全连接网络连接到多模态解码器(LLM)。MLP层维度不变,用于将视觉编码器的输出转换为解码器所需的输入嵌入大小,激活函数为GeLU。
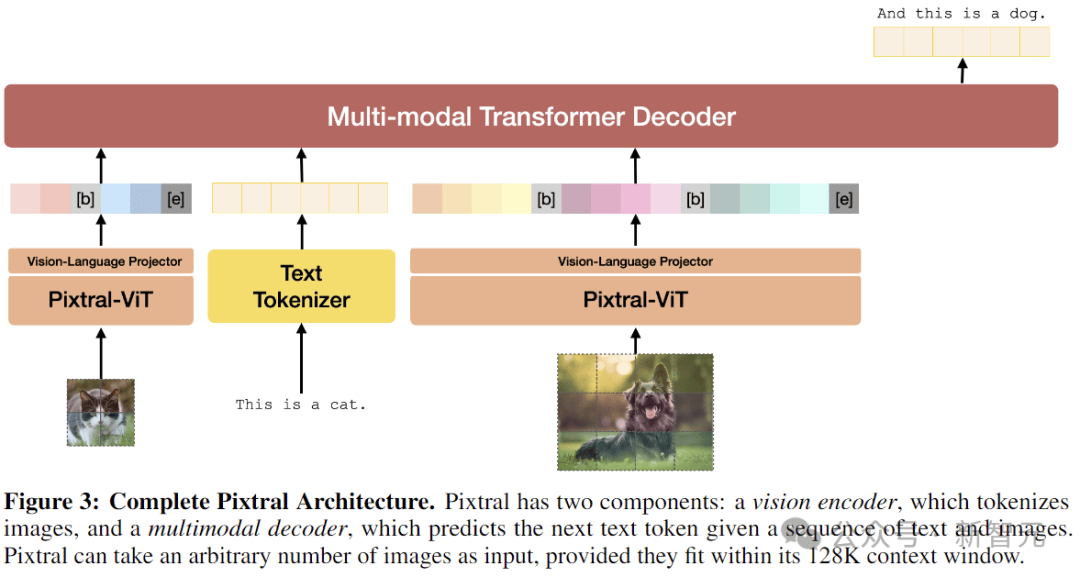
多模态解码器对图像token的处理方式与文本token相同,包括所有token的RoPE-1D位置编码。解码器使用了因果自注意力机制,能够平滑地促进多图像对话等能力。
MM-MT-Bench
大多数现有的多模态基准测试,衡量的是模型在给定输入图像的情况下执行某种形式的多项选择问答的能力。
这种能力有用,但还不够。
大模型说到底是给人用的,比如有多模态能力的小助手或者聊天机器人。
在纯文本领域,MT-Bench可以很好衡量这种性能,它采用独立LLM裁判根据参考答案对模型的输出进行评分。
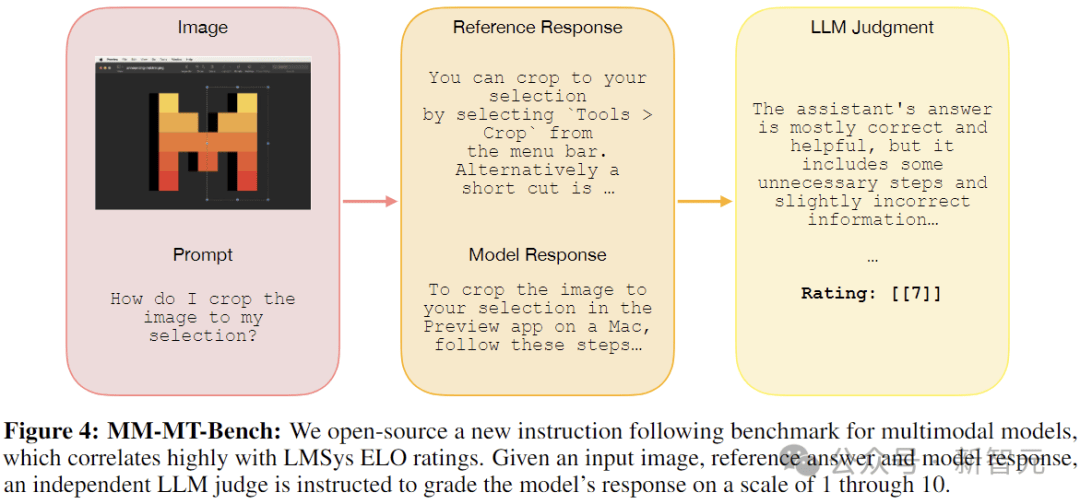
本文中,研究人员构建并发布了一个名为多模态MT-Bench(MM-MT-Bench)的新基准测试,风格与纯文本的MT-Bench类似,以评估指令调整的多模态模型的性能。
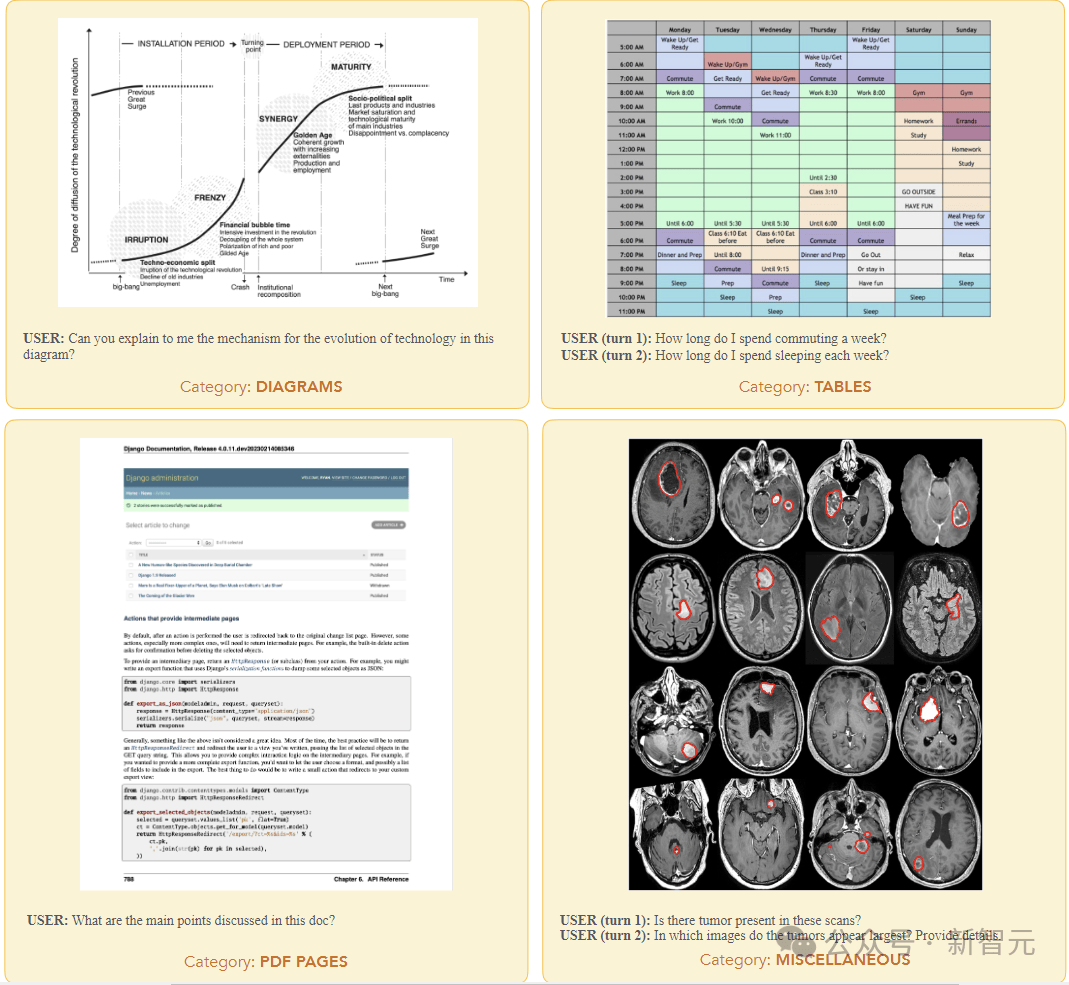
MM-MT-Bench总共包含92个对话(单回合对话69个,2回合对话18个,3回合对话4个,4回合对话1个),涵盖了广泛的实际使用案例,包括五类图像:图表、表格、PDF页面 、示意图和杂项。
为了评估模型,研究人员在对话的所有轮次中并行查询模型,为过去的轮次提供参考答案作为历史记录。裁判会独立对每个回合进行评分,并提供整个对话历史记录。
评分依据正确性(提取的信息是否正确)和完整性(标准答案是否涵盖了参考文献中提出的所有要点)以1到10的等级为对话进行评分。
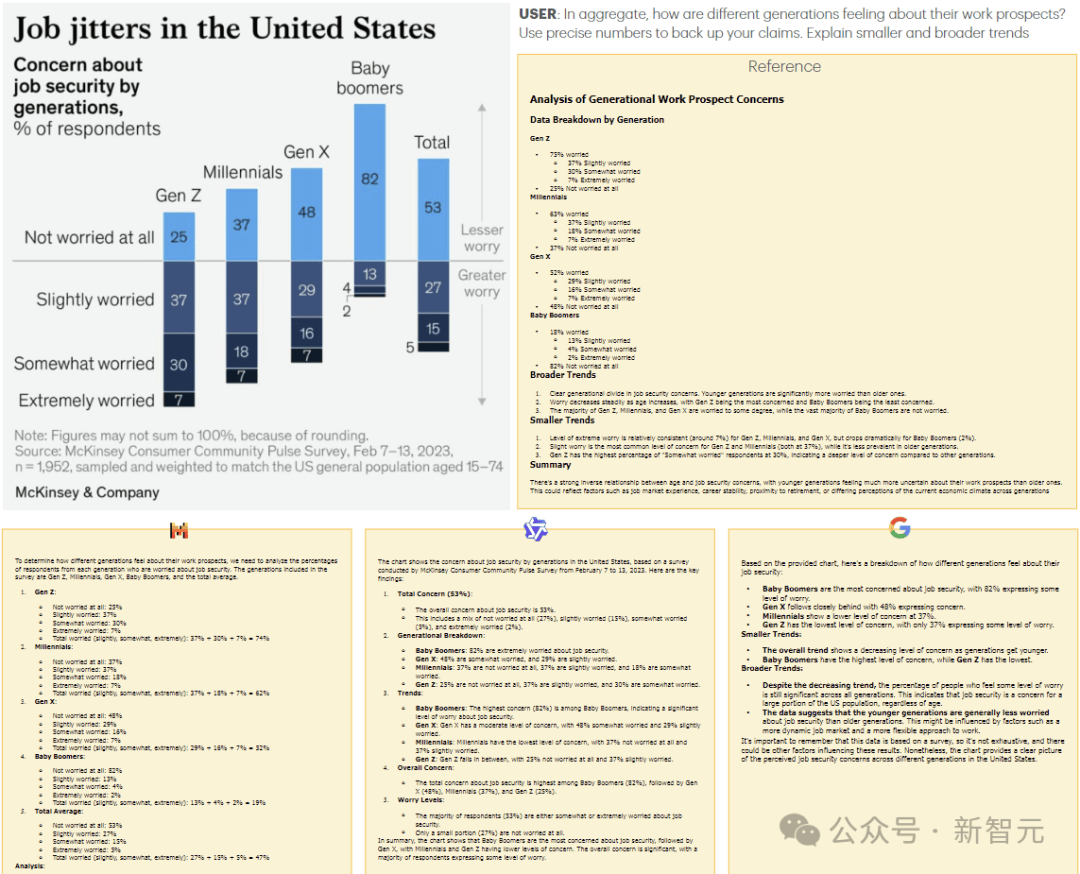
MM-MT-Bench旨在模拟视觉语言模型的实际使用,用于提取、总结和推理图像内容。
作者手动整理了图像、提示和答案,并验证了标签编写者的答案,确保所有提示都需要参考图像输入才能正确回答。
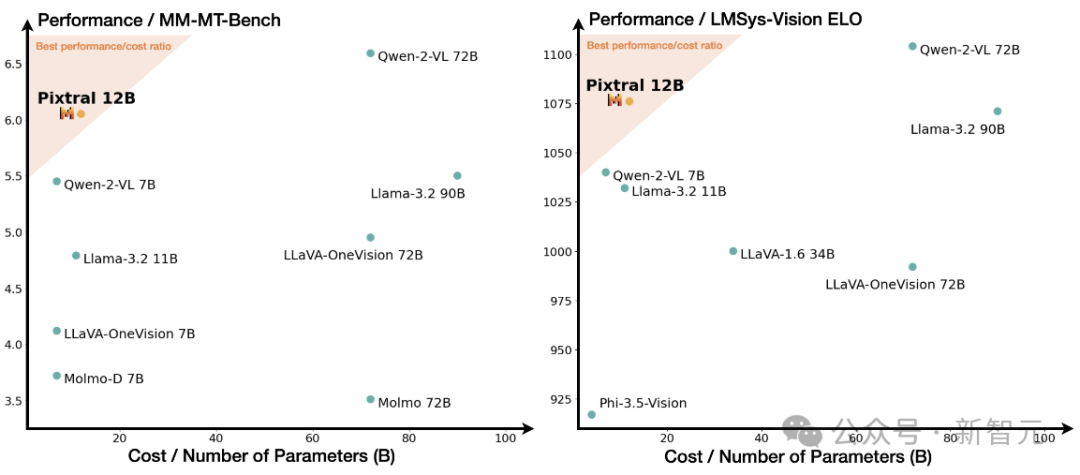
实验测试结果表明,MM-MT-Bench的性能与LMSys Vision排行榜上的ELO排名高度相关。
实验结果
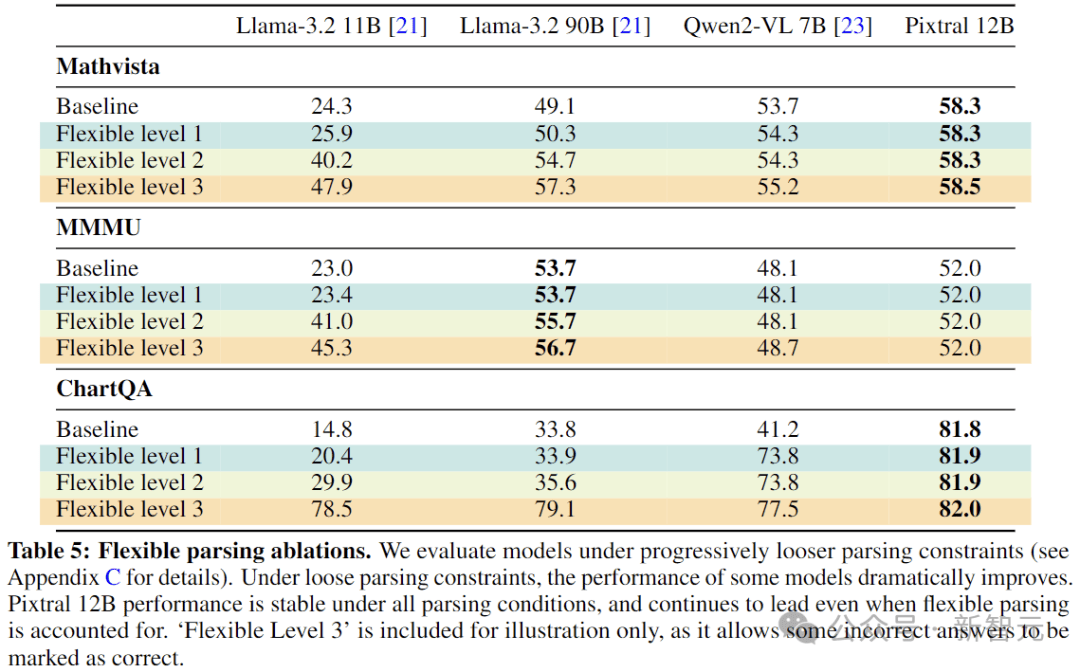
在评估Pixtral和基线的过程中,作者发现多模态模型的评估协议没有标准化,设置中的微小变化可能会极大地改变某些模型的性能(比如要求模型生成与参考答案完全匹配时,6.0和6就可能是不同的)。

为了缓解这个问题,作者建议使用「Explicit」提示来明确指定参考答案所需的格式。
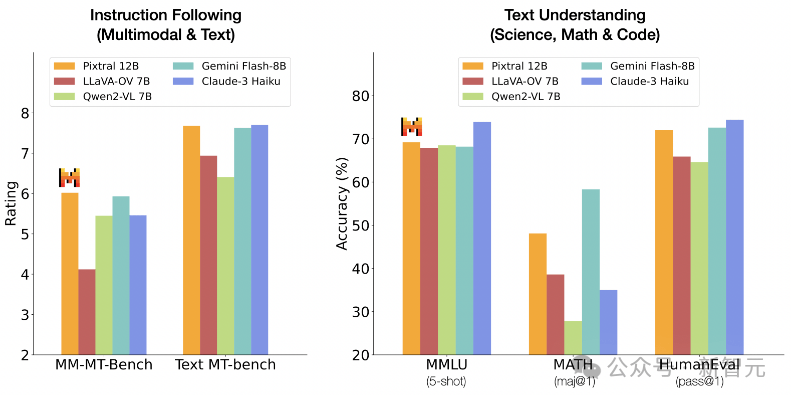
多模态性能
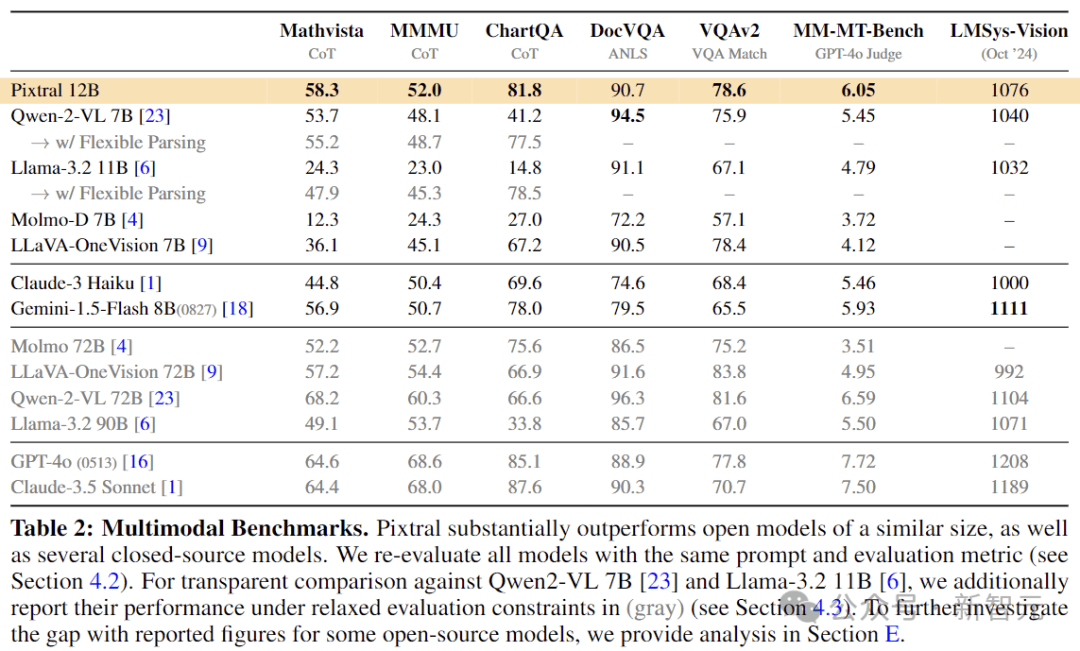
上表显示,在多模态基准测试中,Pixtral的性能大大优于所有同尺寸的开源模型,以及Claude-3 Haiku和Gemini-1.5 Flash 8B等闭源模型。
值得注意的是,Pixtral在针对实际用例的MM-MT-Bench上的表现优于所有同等尺寸的模型,而在LMSys Vision排行榜上,Pixtral 12B的性能接近最大的开源模型,Qwen2-VL 72B和Llama-3.2 90B。
不过,由于「Explicit」提示的原因,一些开源模型的性能远低于其报告的数字,这主要是由于模型没有遵循答案格式说明(例如,生成「The answer is 6.」而不是「Final answer:6」)。
为了与这些模型进行透明的比较,下面使用更宽松的指标进一步评估。
语言性能
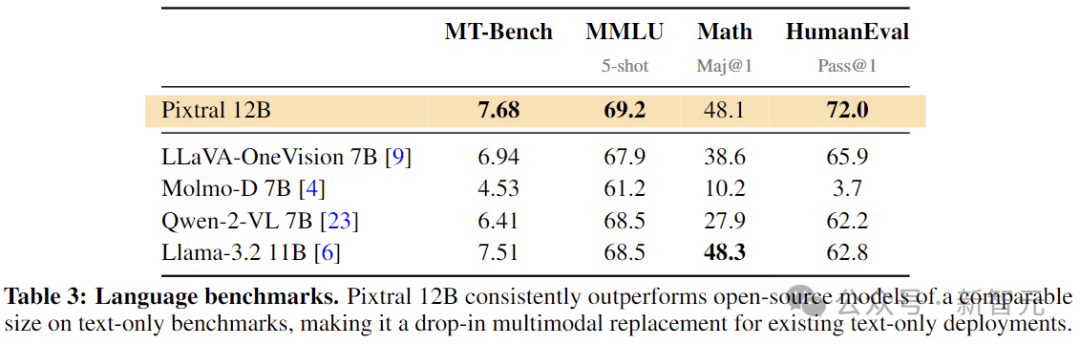
上表展示了在常见的纯文本基准测试(使用常见的提示和评估协议)中,Pixtral 12B与同等大小开源模型的比较结果。Pixtral没有为了追求多模态功能而牺牲文本理解,可以作为文本和视觉任务的通用模型。
参考资料:
https://arxiv.org/abs/2410.07073